Blog
ー
サブエージェントとは何か - 独立した文脈を持つ並列ワーカーの仕組みと使いどころ
2026-06-29 10:26:45
サブエージェントとは、 独立した文脈(コンテキスト)を持つ別のエージェントに、仕事の一部を任せる仕組み です。
ひとつのエージェントだけでは「文脈が膨らみすぎる」「直列で遅い」「役割が混ざる」といった壁にぶつかります。その答えのひとつがサブエージェントです。
この記事では、サブエージェントを 何のために、どう動かし、いつ使うのか を、最小実装を実際に動かしながら説明します。
前提知識は「LLMをAPIで呼んだことがある」程度を想定しています。
サブエージェントとは何か
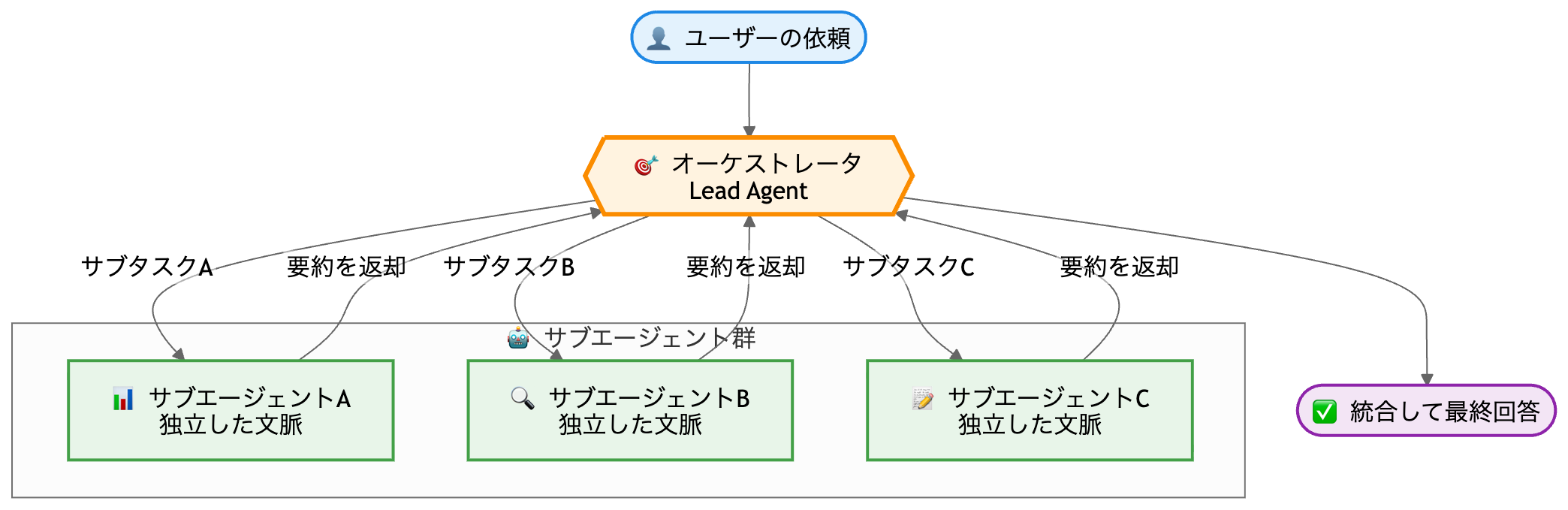
サブエージェントは、 独自のコンテキストウィンドウ・独自のシステムプロンプト・独自のツール を持つ、もう一つのエージェントです。
親(オーケストレータ=lead)が大きな依頼を小さなサブタスクに分解し、それぞれを子(サブエージェント)に渡します。
子は自分の文脈の中で自律的に作業し、 要約だけを親に返します。
Anthropic はこれを orchestrator-worker パターンと呼んでいます [How we built our multi-agent research system]。
ツール呼び出しと何が違うのか
混同しやすいのが「ツール呼び出し」との違いです。
ツールは、 決められた関数を呼ぶ こと(検索する、ファイルを読む、APIを叩く)。
これに対してサブエージェントは、 別の判断主体に「目的」を渡して、やり方ごと委ねる ことです。
ツールは「何をするか」が決まっていますが、サブエージェントは「ゴールだけ伝えて、手順は任せる」。ここが本質的な違いです。
サブエージェントは"オブジェクト"に似ている(が、同じではない)
設計として捉えるなら、サブエージェントはオブジェクト指向の「オブジェクト」に似ています。
各サブは 独立した文脈という"私有状態"を持ち(カプセル化)、外には 要約というメッセージだけ を返し(メッセージパッシング)、 1つの責務 だけを担う(単一責任)。
親はそれらを 組み合わせる(合成)。
Anthropic も各サブエージェントを「関心の分離(distinct tools, prompts, trajectories)」と表現しています。
ただし似ているのはここまでです。
オブジェクトのメソッド呼び出しが 安く・決定的 なのに対し、サブエージェントの呼び出しは 高く・遅く・非決定的のため、「メソッドごとにクラスを切る」感覚で細かく分けると破綻します。
OpenAI も「まず1エージェントから始め、能力や見通しが明確に良くなるときだけ専門エージェントを足せ」と勧めています [A practical guide to building agents]。
境界の引き方(カプセル化・単一責任)はオブジェクト指向に倣ってよいが、どこまで細かく分けるかは倣わない。これが勘所です。
なぜサブエージェントが要るのか
シングルエージェントには、次の3つの限界があります。
- 文脈の肥大:検索結果やログなど冗長な出力が、ひとつの文脈にどんどん溜まる
- 直列の遅さ:1件ずつ順番に処理すると、件数に比例して時間がかかる
- 関心の混在:ひとつの文脈で複数の役割を担うと、判断がぶれる
サブエージェントは、文脈を分けることでこの3つを同時に和らげます。
冗長な出力は子の文脈に閉じ込められ(親は要約だけ受け取る)、子どうしは並列で動き、役割ごとにプロンプトとツールを分けられる。
大きな成果物は、親子間で本文を渡し合わずファイルに保存して参照だけ渡す、という工夫もあります(伝言ゲームの防止)。
要点:サブエージェント=「文脈を分けて、別の判断主体に委譲する」仕組み。ツール呼び出しの延長ではなく、"もう一人に任せる"こと。
どう設計し、いつ使うか
うまく委譲する鍵は、 子に渡す指示の具体性 です。
各サブエージェントには「目的・出力形式・使ってよいツール・担当の境界」を明確に渡します。
これが曖昧だと、複数の子が同じ作業を重複したり、誰も拾わない抜けが出たりします。
Anthropic も、初期に「曖昧な指示で複数サブが同じ検索を繰り返した」失敗を挙げています。
労力はタスクの複雑さに合わせます。Anthropic のスケール則では、単純な事実探索なら1エージェント、直接比較なら2〜4サブ、複雑な調査なら10以上のサブ。
逆に 単純なクエリに50体のサブを生成する ような過剰分割は、それ自体が失敗モードです。
向き/不向きを整理します。
向いている | 向いていない | |
|---|---|---|
タスクの独立性 | 独立・並列可能・自己完結 | 相互依存が強い・リアルタイム協調が必要 |
文脈 | 冗長な出力を隔離したい/単一のコンテキストウィンドウに収まらない | 全員が同じ文脈を共有する必要がある |
代表例 | 広く浅い調査、複数ソースの並行収集、大量ログの処理 | 多くのコーディング作業、同一ファイルの並行編集 |
「2人の担当者に同時に渡せて、事前に相談しなくても進む仕事」なら並列向き。
「ひとつのファイルを2人で同時に書き換える」ような仕事は、分けると壊れます。
なお、子はそれぞれ独立した文脈を持つぶん トークンは増えます(節約の道具ではありません)。だからこそ、価値の高いタスクに絞って使います。
設計の具体例:工程で割らず、役割で割る
レポートを作るタスクを、 工程ごと に 検索 /重複除去 /要約 /整形 と別エージェントに割るのは やりすぎ です。
ただの関数で済む部分までエージェント化し、コストと伝言ゲームが膨らみます。良い設計は、 役割ごとに粗く 割ることです。
// 擬似コード(構造を示すためのスケッチ)
class SearchWorker { // 単一責任:あるサブテーマを調べ、要約だけ返す
String run(String subtopic) {
// 生の検索結果は自分の文脈に閉じ込める(カプセル化)
return summary; // 親に返すのは要約だけ(メッセージパッシング)
}
}
class Orchestrator { // 合成:ワーカーを組み合わせるだけ。自分では検索しない
String run(String query) {
List<String> plan = plan(query); // 分解
List<String> findings = parallel(SearchWorker::run, plan); // 独立サブを並列実行
return synthesize(findings); // 統合
}
}割る単位は 役割(数個)であって工程ではない。
Anthropic のスケール則(単純=1/比較=2〜4/複雑=10+)も、この粗さに合っています。
なお、こうしたサブエージェントを組み合わせる オーケストレーションの構成パターン(routing・parallelization・orchestrator-workers など)は、次回別記事で整理します。
要点:委譲は「ゴール・出力形式・ツール・境界」をセットで渡す。 役割で粗く割り、工程で細かく割らない。複雑さに労力を合わせ、過剰に分けない。
判断は「出費」ではなく「容量」- 各モデルのコンテキストウィンドウと日本語の目安
そもそもコンテキストウィンドウとは
コンテキストウィンドウは、LLMが1回のやり取りで 一度に見られるテキストの上限(トークン数) です。
人間でいう「机の広さ」のようなもので、その上に載っているものだけを材料に答えを作ります。
そして載るのは入力テキストだけではありません。1回のリクエストでこの枠に同居するのは、ざっくり次の全部です。
- システムプロンプト/指示(モデルへの役割やルール)
- 会話履歴(これまでのやり取り。ターンを重ねるほど増える)
- ツールの定義とその実行結果(使えるツールの一覧、検索やコードの出力)
- 今回の入力(ユーザーの依頼、添付したドキュメントなど)
- モデルが生成する出力(推論モデルなら、加えて内部の思考トークン)
これらの 合計 が上限を超えると、もう入りません(古い部分から切り捨てられます)。
つまり「コンテキストウィンドウに収まるか」は、今回の入力の長さだけでなく、指示・会話履歴・ツールの結果・出力まで足した総量で決まります。
会話が長く続いたり、ツールの出力が多いほど、この枠は静かに埋まっていきます。
混同しやすい区別を一つ。サブエージェントを使うかどうかは、 消費トークンを減らしたいか で決めるのではありません(むしろ増えます)。
決め手は「コンテキストウィンドウ(=1回に積める上限=容量)が上限に達するか」です。
- 容量(コンテキストウィンドウ):1つのLLMが一度に保持できる上限。ここを超えると物理的に入らない。
- 出費(総トークン消費):全呼び出しの合計の支払い。サブエージェントはこれを 増やす(プロンプトや要約が体の数だけ重複する)。
サブエージェントは 容量の問題を解く道具 で、その代わりに出費は増えます。
だから「トークンを減らしたい」が目的なら、使うのは逆です。
その場合はモデルルーティング(簡単な所は安いモデル)・コンテキスト圧縮・キャッシュといった別の道具を使います。
では、その「容量」は実際どれくらいか。主要モデルの現在のコンテキストウィンドウと、日本語の目安です。
モデル | コンテキストウィンドウ | 日本語の目安 |
|---|---|---|
Claude Opus 4.8 / Sonnet 4.6 | 100万トークン | 約100万字(文庫本 約7〜10冊) |
GPT-5.5 | 100万トークン(API) | 約100万字 |
Gemini 3 Pro | 100万〜200万トークン | 約100万〜200万字 |
トークンと日本語の関係(もう少し詳しく)
そもそも「トークン」は文字でも単語でもなく、モデルが扱う サブワード単位 です(頻出する文字の並びを1つにまとめたもの=BPE[Byte Pair Encoding])。
だから言語によって「1文字あたり何トークンか」が大きく変わります。
- 英語:1トークン ≈ 4文字(≒ 0.75単語)。頻出単語はまるごと1トークンになる。
- 日本語:おおむね 1文字 ≈ 1トークン(1,000文字 ≈ 約1,000トークン)。ひらがな・カタカナ・漢字いずれも、英語ほど効率よくまとまらないため。
学習データに少ない 珍しい漢字 はバイト単位に分解され、 1文字で2〜3トークン になることも。
逆に「です」「ます」のような頻出の並びは1トークンにまとまることもある。
結果として、 同じ内容でも日本語は英語の約3〜4倍のトークン を食います。
これは料金(出費)にも、コンテキストウィンドウに入るか(容量)にも、そのまま効きます。
100万トークンのコンテキストウィンドウは、日本語ならざっくり100万字弱が目安。
実例として、この記事自身を [OpenAIのトークナイザ](GPT-5.x / o1・o3 = o200k_base)で数えると、 32,040文字で 12,376トークン でした(1文字あたり約 0.39トークン)。
地の文だけなら約1トークン/文字ですが、この記事は コード・英語の専門用語・表やURL を含むぶん、その部分が効率よくまとまって全体では1文字未満に下がります。
感覚としては「日本語の地の文は1文字 ≒ 1トークン、コードや英数字が混じるとそれより軽くなる」。
正確に知りたいときは、上のトークナイザに実際に貼って数えるのが手早いです。
トークナイザはモデルごとに違います。
OpenAIのGPT-4o/5系は o200k_base、旧GPT-4系は cl100k_base。Claude・Gemini はそれぞれ独自のトークナイザを持ち、同じ文章でも数は5〜10%ほどズレます。
新しい o200k は多言語の圧縮を改善しましたが(アラビア語などは大幅減)、 日本語などCJKはおおむね1:1のまま で、ここは大きく変わっていません。
料金やコンテキストウィンドウの上限がシビアな場面では、概算ではなく そのモデルの公式の方法で実際に数える のが安全です。
つまり現行モデルのコンテキストウィンドウは広く、 たいていの単発タスクは1つに収まります。
サブエージェントが容量の理由で要るのは、この100万トークン級すら超える(大量の長文を横断する)、あるいはエージェントが長く動いて文脈が膨れ続けるようなときだけです。
注意:プロンプトのトークンは「下限」にすぎない
ここで数えたのは 送るテキストのトークンだけ で、実際の消費はこれより増えます。
推論モデル(o3 / GPT-5系の思考、Claude の extended thinking)は答えを出す前に 内部の思考トークン を生成し、これは見えなくても 出力と同じ単価で課金 されます。
複雑な要求では 1回で2〜4万トークン に達することもあり、OpenAI は GPT-5.5 で「推論用に25,000トークン以上を空けておけ」と推奨しています(しかもプロンプトキャッシュは入力には効きますが、思考トークンには効きません)。
さらにエージェントはツールを呼ぶたびに履歴を読み直すので、ステップが増えるほど入力も積み上がります。
冒頭で触れた「エージェントは約4倍、マルチは約15倍のトークンを食う」は、まさにこの内部消費が効いた数字です。
思考トークンは 1回のリクエストの中で出力トークンと同じコンテキストウィンドウを奪い合います(ターンをまたぐと破棄されるので累積はしません)。
だから「100万のコンテキストウィンドウだから100万字弱入る」と思っても、推論ぶんの空き(数万トークン)は別に確保しておく必要があります。
静的な文字数は“下限”であって、実際の請求やコンテキストウィンドウの消費はそれより大きい と見ておくのが安全です。
実検証:サブエージェントが「あると便利」ではなく「ないと無理」になる規模
先に正直に言うと、“数件の問い合わせを要約する”程度なら、サブエージェントもLLMも要りません。
普通の関数で十分で、わざわざ分けるのは複雑にするだけです。
サブエージェントが容量の理由で効くのは、 現行モデルの広いコンテキストウィンドウ(後述の100万トークン級)すら超える ほどタスクが大きいときだけ。
そこを、GPT・Claude・Gemini でトークン数を検証し、規模を変えてトークン数を検証するサンプルコードを用意しました。
題材と見積もりコード
題材は「江戸川乱歩の長編小説を何冊も横断して、傾向をまとめる」。
対象とするタイトルは下記です。
- D坂の殺人事件
- 黄金仮面
- 少年探偵団
- 怪人二十面相
- 透明怪人
- 妖怪博士
- 青銅の魔人
- 奇面城の秘密
(a) シングルエージェントが全冊をまとめて問い合わせる場合と、(b) サブエージェントが1体1冊ずつ別々の文脈で読み、要約だけ親に返す場合の、 ピークのコンテキスト量 を見積もります。
import java.util.List;
import java.util.stream.Collectors;
public final class ComparisonPrompts {
private ComparisonPrompts() {}
public record DocumentInput(String title, String author, String genre, String fullText) {}
public record DocumentSummary(String title, String summary) {}
public static String buildSingleAgentBatchAnalysisPrompt(List<DocumentInput> documents) {
String documentText =
documents.stream()
.map(
doc ->
"""
# 文献: %s
著者: %s
ジャンル: %s
## 本文
%s
"""
.formatted(
doc.title(),
emptyIfNull(doc.author()),
emptyIfNull(doc.genre()),
emptyIfNull(doc.fullText())))
.collect(Collectors.joining("\n\n---\n\n"));
return """
あなたは複数文献の横断分析を行うシングルエージェントです。
以下に全ての文献本文を一括で提示します。
このプロンプト内の文献本文だけを根拠に横断分析してください。
目的は、単一文献の要約ではなく、
複数文献をまたいで見える共通点・相違点・傾向・構造を明らかにすることです。
## 分析観点
1. 共通テーマ
2. 頻出概念
3. 共通する構造
4. 文献ごとの差異
5. 著者・語り手・立場による違い
6. 主張の共通点
7. 主張の相違点
8. 時代背景や文脈による違い
9. 読者への影響
10. 特徴的なパターン
11. 全体から得られる知見
12. 今後さらに調べるべき論点
## 出力形式
## 1. 全体要約
## 2. 共通点
## 3. 相違点
## 4. 文献別特徴一覧
| 文献 | 主題 | 主な特徴 | 独自性 | 他文献との差分 |
|---|---|---|---|---|
## 5. 頻出テーマ
## 6. 頻出概念
## 7. 構造上の共通点
## 8. 構造上の違い
## 9. 横断的な知見
## 10. 結論
## 注意
- 推測ではなく、提示された文献本文の内容に基づいて分析してください。
- 本文に根拠がない内容は断定しないでください。
- 文献紹介ではなく、横断分析をしてください。
- 日本語で出力してください。
# 文献本文
%s
""".formatted(documentText);
}
public static String buildSubAgentSummaryPrompt(DocumentInput doc) {
return """
あなたは文献分析サブエージェントです。
担当する文献は1件のみです。
後続の親エージェントが複数文献を横断分析できるよう、
重要情報を抽出して構造化要約を作成してください。
## 重要な方針
- 他文献との比較はしないでください。
- この文献単体から読み取れる内容だけを書いてください。
- 親エージェントが横断分析しやすいように、簡潔かつ情報密度高くまとめてください。
- 事実、解釈、注目点を分けてください。
- 不明な項目は無理に補完せず「不明」と書いてください。
- 日本語で出力してください。
## 出力形式
## 1. 基本情報
- タイトル:
- 著者:
- ジャンル:
- 想定読者:
## 2. 全体要約
## 3. 主要トピック
## 4. 重要な概念
## 5. 重要な人物・主体・組織
## 6. 重要な出来事・論点
## 7. 主張・メッセージ
## 8. 構造上の特徴
## 9. 頻出テーマ
## 10. 頻出モチーフ
## 11. 文体・語り口・説明スタイル
## 12. 他文献との比較で重要になりそうな特徴
## 13. 注意すべき解釈ポイント
## 14. この文献を一言で表すと
## 文献情報
タイトル: %s
著者: %s
ジャンル: %s
## 本文
%s
"""
.formatted(
doc.title(),
emptyIfNull(doc.author()),
emptyIfNull(doc.genre()),
emptyIfNull(doc.fullText()));
}
public static String buildParentCrossAnalysisPrompt(List<DocumentSummary> summaries) {
String summaryText =
summaries.stream()
.map(
s ->
"""
# 文献: %s
%s
"""
.formatted(s.title(), s.summary()))
.collect(Collectors.joining("\n\n---\n\n"));
return """
あなたは複数文献の横断分析エージェントです。
以下は、各サブエージェントが1文献ずつ読んで作成した構造化要約です。
あなたは本文全文ではなく、これらの要約だけを使って横断分析してください。
目的は、複数文献をまたいで見える
共通点・相違点・傾向・構造・重要な示唆を明らかにすることです。
## 分析観点
1. 共通テーマ
2. 共通概念
3. 相違点
4. 特徴的なパターン
5. 頻出モチーフ
6. 構造上の共通点
7. 構造上の差異
8. 主張やメッセージの共通点
9. 主張やメッセージの相違点
10. 全体から得られる知見
11. 重要な示唆
12. 今後さらに調べるべき論点
## 出力形式
## 1. 全体要約
## 2. 共通点
## 3. 相違点
## 4. 文献別特徴表
| 文献 | 主題 | 特徴 | 独自性 | 他文献との差分 |
|---|---|---|---|---|
## 5. 頻出テーマ
## 6. 頻出概念
## 7. 構造上の共通点
## 8. 構造上の差異
## 9. 横断的な発見
## 10. 重要な示唆
## 11. 結論
## 注意
- 要約に存在しない内容を推測で補わないでください。
- 根拠は要約に含まれる情報に限定してください。
- 根拠が弱い場合は「要約から見る限り」と明記してください。
- 文献紹介ではなく、横断分析をしてください。
- 日本語で出力してください。
# 文献要約
%s
""".formatted(summaryText);
}
private static String emptyIfNull(String value) {
return value == null ? "" : value;
}
}import com.anthropic.client.AnthropicClient;
import com.anthropic.client.okhttp.AnthropicOkHttpClient;
import com.anthropic.models.messages.MessageCountTokensParams;
import com.google.common.base.Splitter;
import com.google.common.collect.ImmutableMap;
import com.google.genai.Client;
import com.openai.client.OpenAIClient;
import com.openai.client.okhttp.OpenAIOkHttpClient;
import com.openai.models.responses.inputtokens.InputTokenCountParams;
import java.io.IOException;
import java.nio.charset.Charset;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.Comparator;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Locale;
import java.util.Map;
import java.util.stream.Collectors;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.lang3.Strings;
public class TokenComparison {
public record TokenReport(long totalInputTokens, long peakContextTokens) {}
public enum Provider {
OPENAI,
ANTHROPIC,
GEMINI
}
public record ProviderModel(Provider provider, String label, String modelId) {}
public interface TokenCounter {
long countInputTokens(String model, String prompt);
}
public static final class OpenAiInputTokenCounter implements TokenCounter {
private final OpenAIClient client = OpenAIOkHttpClient.fromEnv();
@Override
public long countInputTokens(String model, String prompt) {
return client
.responses()
.inputTokens()
.count(InputTokenCountParams.builder().model(model).input(prompt).build())
.inputTokens();
}
}
public static final class AnthropicInputTokenCounter implements TokenCounter {
private final AnthropicClient client = AnthropicOkHttpClient.fromEnv();
@Override
public long countInputTokens(String model, String prompt) {
return client
.messages()
.countTokens(MessageCountTokensParams.builder().model(model).addUserMessage(prompt).build())
.inputTokens();
}
}
public static final class GeminiInputTokenCounter implements TokenCounter {
private final Client client = new Client();
@Override
public long countInputTokens(String model, String prompt) {
return client.models.countTokens(model, prompt, null).totalTokens().orElse(0);
}
}
public static TokenReport measureSingleAgent(
ProviderModel providerModel,
List<ComparisonPrompts.DocumentInput> documents,
TokenCounter tokenCounter) {
var report = new MutableTokenReport();
System.out.printf("%n=== シングルエージェント方式: %s / %s ===%n", providerModel.label(), providerModel.modelId());
long tokens = tokenCounter.countInputTokens(providerModel.modelId(), ComparisonPrompts.buildSingleAgentBatchAnalysisPrompt(documents));
report.addIndependentContext(tokens);
System.out.printf("[single/batch-final] documents=%d inputTokens=%d peakContextTokens=%d%n", documents.size(), tokens, report.peakContextTokens);
return report.toRecord();
}
public static TokenReport measureSubAgents(
ProviderModel providerModel,
List<ComparisonPrompts.DocumentInput> documents,
List<ComparisonPrompts.DocumentSummary> summaries,
TokenCounter tokenCounter) {
var report = new MutableTokenReport();
System.out.printf("%n=== サブエージェント方式: %s / %s ===%n", providerModel.label(), providerModel.modelId());
for (ComparisonPrompts.DocumentInput doc : documents) {
long tokens = tokenCounter.countInputTokens(providerModel.modelId(), ComparisonPrompts.buildSubAgentSummaryPrompt(doc));
report.addIndependentContext(tokens);
System.out.printf("[sub/summary] title=%s inputTokens=%d peakContextTokens=%d%n", doc.title(), tokens, report.peakContextTokens);
}
long parentTokens = tokenCounter.countInputTokens(providerModel.modelId(), ComparisonPrompts.buildParentCrossAnalysisPrompt(summaries));
report.addIndependentContext(parentTokens);
System.out.printf("[parent/final] inputTokens=%d peakContextTokens=%d%n", parentTokens, report.peakContextTokens);
return report.toRecord();
}
private static final class MutableTokenReport {
long totalInputTokens;
long peakContextTokens;
void addIndependentContext(long tokens) {
totalInputTokens += tokens;
peakContextTokens = Math.max(peakContextTokens, tokens);
}
TokenReport toRecord() {
return new TokenReport(totalInputTokens, peakContextTokens);
}
}
public static void printComparison(ProviderModel providerModel, TokenReport single, TokenReport sub) {
System.out.printf("%n=== 比較結果: %s / %s ===%n", providerModel.label(), providerModel.modelId());
System.out.printf("シングルエージェント totalInputTokens=%d%n", single.totalInputTokens());
System.out.printf("シングルエージェント peakContextTokens=%d%n", single.peakContextTokens());
System.out.printf("サブエージェント totalInputTokens=%d%n", sub.totalInputTokens());
System.out.printf("サブエージェント peakContextTokens=%d%n", sub.peakContextTokens());
System.out.printf("ピークコンテキスト削減率=%.2f%%%n", reductionRate(single, sub) * 100.0);
}
public static void printSummaryTable(Map<ProviderModel, TokenReport> singleReports, Map<ProviderModel, TokenReport> subReports) {
System.out.println("\n=== モデル別サマリー ===");
System.out.println("| Provider | Model | Single total | Single peak | Sub total | Sub peak | Peak reduction |");
System.out.println("|---|---|---:|---:|---:|---:|---:|");
singleReports.forEach(
(pm, single) -> {
TokenReport sub = subReports.get(pm);
System.out.printf("| %s | %s | %d | %d | %d | %d | %.2f%% |%n", pm.label(), pm.modelId(), single.totalInputTokens(), single.peakContextTokens(), sub.totalInputTokens(), sub.peakContextTokens(), reductionRate(single, sub) * 100.0);
});
}
private static double reductionRate(TokenReport single, TokenReport sub) {
return single.peakContextTokens() == 0 ? 0.0 : 1.0 - (double) sub.peakContextTokens() / single.peakContextTokens();
}
private static TokenCounter tokenCounterFor(Provider provider) {
return switch (provider) {
case OPENAI -> new OpenAiInputTokenCounter();
case ANTHROPIC -> new AnthropicInputTokenCounter();
case GEMINI -> new GeminiInputTokenCounter();
};
}
private static List<ComparisonPrompts.DocumentInput> loadDocumentsFromDirectory(Path documentsDir, Charset charset) throws IOException {
try (var paths = Files.list(documentsDir)) {
return paths
.filter(Files::isRegularFile)
.filter(path -> path.getFileName().toString().endsWith(".txt"))
.sorted(Comparator.comparing(path -> path.getFileName().toString()))
.map(path -> readDocumentFile(path, charset))
.toList();
}
}
private static ComparisonPrompts.DocumentInput readDocumentFile(Path file, Charset charset) {
ParsedText parsed = parseFrontMatter(readString(file, charset));
String body = parsed.body();
String title = StringUtils.defaultIfBlank(parsed.metadata().get("title"), firstNonBlankLine(body));
String author = StringUtils.defaultIfBlank(parsed.metadata().get("author"), nthNonBlankLine(body, 2));
String genre = StringUtils.defaultString(parsed.metadata().get("genre"));
return new ComparisonPrompts.DocumentInput(StringUtils.defaultIfBlank(title, stripExtension(file.getFileName().toString())), author, genre, body);
}
private static List<ComparisonPrompts.DocumentSummary> loadSummariesFromDirectory(Path summariesDir, List<ComparisonPrompts.DocumentInput> documents, Charset charset) throws IOException {
Map<String, String> summaryByTitle;
try (var paths = Files.list(summariesDir)) {
summaryByTitle = paths
.filter(Files::isRegularFile)
.filter(path -> path.getFileName().toString().endsWith(".txt"))
.sorted(Comparator.comparing(path -> path.getFileName().toString()))
.map(path -> Map.entry(detectSummaryTitle(path, charset), parseFrontMatter(readString(path, charset)).body()))
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (left, right) -> left));
}
return documents.stream()
.map(doc -> new ComparisonPrompts.DocumentSummary(doc.title(), StringUtils.defaultIfBlank(summaryByTitle.get(doc.title()), fallbackSummary(doc.fullText()))))
.toList();
}
private static List<ComparisonPrompts.DocumentSummary> buildFallbackSummaries(List<ComparisonPrompts.DocumentInput> documents) {
return documents.stream().map(doc -> new ComparisonPrompts.DocumentSummary(doc.title(), fallbackSummary(doc.fullText()))).toList();
}
private static String fallbackSummary(String text) {
return """
## 注意
要約ファイルがないため、本文冒頭から仮要約を作っています。
## 仮要約
%s
""".formatted(StringUtils.abbreviate(text, 1_000));
}
private record ParsedText(Map<String, String> metadata, String body) {}
private static ParsedText parseFrontMatter(String raw) {
String normalized = StringUtils.replaceEach(raw, new String[] {"\r\n", "\r"}, new String[] {"\n", "\n"});
if (!normalized.startsWith("---\n") || !normalized.substring(4).contains("\n---\n")) {
return new ParsedText(Map.of(), normalized);
}
String metadataBlock = StringUtils.substringBetween(normalized, "---\n", "\n---\n");
String body = StringUtils.substringAfter(normalized, "\n---\n");
Map<String, String> metadata = Splitter.on('\n').omitEmptyStrings().splitToStream(metadataBlock)
.map(line -> StringUtils.splitByWholeSeparator(line, ":", 2))
.filter(parts -> parts.length == 2)
.collect(ImmutableMap.toImmutableMap(parts -> parts[0].trim().toLowerCase(Locale.ROOT), parts -> parts[1].trim(), (left, right) -> left));
return new ParsedText(metadata, body);
}
private static String detectSummaryTitle(Path path, Charset charset) {
ParsedText parsed = parseFrontMatter(readString(path, charset));
return StringUtils.firstNonBlank(parsed.metadata().get("title"), extractLabeledValue(parsed.body(), "タイトル"), firstNonHeadingLine(parsed.body()), stripExtension(path.getFileName().toString()));
}
private static String extractLabeledValue(String text, String label) {
return Splitter.on('\n').splitToStream(StringUtils.defaultString(text))
.map(line -> Strings.CS.removeStart(Strings.CS.removeStart(line.trim(), "- "), "* "))
.filter(line -> Strings.CI.startsWithAny(line, label + ":", label + ":"))
.map(line -> line.replaceFirst("^[^::]*[::]", "").trim())
.findFirst()
.orElse("");
}
private static String firstNonBlankLine(String text) {
return nthNonBlankLine(text, 1);
}
private static String firstNonHeadingLine(String text) {
return Splitter.on('\n').trimResults().omitEmptyStrings().splitToStream(StringUtils.defaultString(text)).filter(line -> !line.startsWith("#")).findFirst().orElse("");
}
private static String nthNonBlankLine(String text, int n) {
return Splitter.on('\n').trimResults().omitEmptyStrings().splitToStream(StringUtils.defaultString(text)).skip(n - 1L).findFirst().orElse("");
}
private static String stripExtension(String fileName) {
return StringUtils.substringBeforeLast(fileName, ".");
}
private static String readString(Path path, Charset charset) {
try {
return Files.readString(path, charset);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) throws IOException {
List<ProviderModel> providerModels = List.of(
new ProviderModel(Provider.OPENAI, "GPT", "gpt-5.5"),
new ProviderModel(Provider.ANTHROPIC, "Claude Opus", "claude-opus-4-8"),
new ProviderModel(Provider.GEMINI, "Gemini", "gemini-3.5-flash"));
Path baseDir = Path.of(System.getProperty("user.dir")).resolve("ルートディレクトリを指定");
Path documentsDir = args.length >= 1 ? Path.of(args[0]) : baseDir.resolve("documents");
Path summariesDir = args.length >= 2 ? Path.of(args[1]) : baseDir.resolve("summaries");
Charset documentsCharset = args.length >= 3 ? Charset.forName(args[2]) : Charset.forName("Shift_JIS");
Charset summariesCharset = args.length >= 4 ? Charset.forName(args[3]) : Charset.forName("UTF-8");
List<ComparisonPrompts.DocumentInput> documents = loadDocumentsFromDirectory(documentsDir, documentsCharset);
List<ComparisonPrompts.DocumentSummary> summaries = Files.isDirectory(summariesDir) ? loadSummariesFromDirectory(summariesDir, documents, summariesCharset) : buildFallbackSummaries(documents);
System.out.printf("Loaded documents: %d%nDocuments charset: %s%nSummaries charset: %s%n", documents.size(), documentsCharset, summariesCharset);
var singleReports = new LinkedHashMap<ProviderModel, TokenReport>();
var subReports = new LinkedHashMap<ProviderModel, TokenReport>();
for (ProviderModel providerModel : providerModels) {
TokenCounter counter = tokenCounterFor(providerModel.provider());
TokenReport single = measureSingleAgent(providerModel, documents, counter);
TokenReport sub = measureSubAgents(providerModel, documents, summaries, counter);
printComparison(providerModel, single, sub);
singleReports.put(providerModel, single);
subReports.put(providerModel, sub);
}
printSummaryTable(singleReports, subReports);
}
}出力結果
=== シングルエージェント方式: GPT / gpt-5.5 ===
[single/batch-final] documents=8 inputTokens=643792 peakContextTokens=643792
=== サブエージェント方式: GPT / gpt-5.5 ===
[sub/summary] title=D坂の殺人事件 inputTokens=19549 peakContextTokens=19549
[sub/summary] title=怪人二十面相 inputTokens=91981 peakContextTokens=91981
[sub/summary] title=奇面城の秘密 inputTokens=62187 peakContextTokens=91981
[sub/summary] title=黄金仮面 inputTokens=132213 peakContextTokens=132213
[sub/summary] title=青銅の魔人 inputTokens=68678 peakContextTokens=132213
[sub/summary] title=少年探偵団 inputTokens=84177 peakContextTokens=132213
[sub/summary] title=透明怪人 inputTokens=80320 peakContextTokens=132213
[sub/summary] title=妖怪博士 inputTokens=107276 peakContextTokens=132213
[parent/final] inputTokens=30029 peakContextTokens=132213
=== 比較結果: GPT / gpt-5.5 ===
シングルエージェント totalInputTokens=643792
シングルエージェント peakContextTokens=643792
サブエージェント totalInputTokens=676410
サブエージェント peakContextTokens=132213
ピークコンテキスト削減率=79.46%
=== シングルエージェント方式: Claude Opus / claude-opus-4-8 ===
[single/batch-final] documents=8 inputTokens=787262 peakContextTokens=787262
=== サブエージェント方式: Claude Opus / claude-opus-4-8 ===
[sub/summary] title=D坂の殺人事件 inputTokens=23656 peakContextTokens=23656
[sub/summary] title=怪人二十面相 inputTokens=112892 peakContextTokens=112892
[sub/summary] title=奇面城の秘密 inputTokens=75717 peakContextTokens=112892
[sub/summary] title=黄金仮面 inputTokens=160905 peakContextTokens=160905
[sub/summary] title=青銅の魔人 inputTokens=83841 peakContextTokens=160905
[sub/summary] title=少年探偵団 inputTokens=103535 peakContextTokens=160905
[sub/summary] title=透明怪人 inputTokens=98023 peakContextTokens=160905
[sub/summary] title=妖怪博士 inputTokens=131876 peakContextTokens=160905
[parent/final] inputTokens=36633 peakContextTokens=160905
=== 比較結果: Claude Opus / claude-opus-4-8 ===
シングルエージェント totalInputTokens=787262
シングルエージェント peakContextTokens=787262
サブエージェント totalInputTokens=827078
サブエージェント peakContextTokens=160905
ピークコンテキスト削減率=79.56%
=== シングルエージェント方式: Gemini / gemini-3.5-flash ===
[single/batch-final] documents=8 inputTokens=530920 peakContextTokens=530920
=== サブエージェント方式: Gemini / gemini-3.5-flash ===
[sub/summary] title=D坂の殺人事件 inputTokens=15562 peakContextTokens=15562
[sub/summary] title=怪人二十面相 inputTokens=76305 peakContextTokens=76305
[sub/summary] title=奇面城の秘密 inputTokens=51957 peakContextTokens=76305
[sub/summary] title=黄金仮面 inputTokens=109751 peakContextTokens=109751
[sub/summary] title=青銅の魔人 inputTokens=56232 peakContextTokens=109751
[sub/summary] title=少年探偵団 inputTokens=69588 peakContextTokens=109751
[sub/summary] title=透明怪人 inputTokens=66442 peakContextTokens=109751
[sub/summary] title=妖怪博士 inputTokens=87254 peakContextTokens=109751
[parent/final] inputTokens=24717 peakContextTokens=109751
=== 比較結果: Gemini / gemini-3.5-flash ===
シングルエージェント totalInputTokens=530920
シングルエージェント peakContextTokens=530920
サブエージェント totalInputTokens=557808
サブエージェント peakContextTokens=109751
ピークコンテキスト削減率=79.33%結果の読み取り
シングルエージェントは約53-80万トークンとなったため、あと2倍(16冊)の本を一気に扱うとコンテキストウィンドウ上限を超えそうです。
一方サブエージェントは1体あたり 150,000 トークン(1冊ぶん)に収まり、冊数が増えても破綻しない。
ここで初めてサブエージェントは「あると便利」ではなく「ないと成り立たない」になります。
数冊のときに不要だったのは、単にコンテキストウィンドウに余裕で収まっていたからです。
Provider | Model | Single total | Single peak | Sub total | Sub peak | Peak reduction |
|---|---|---|---|---|---|---|
GPT | gpt-5.5 | 643792 | 643792 | 676410 | 132213 | 79.46% |
Claude Opus | claude-opus-4-8 | 787262 | 787262 | 827078 | 160905 | 79.56% |
Gemini | gemini-3.5-flash | 530920 | 530920 | 557808 | 109751 | 79.33% |
要点:サブエージェントは“速くする道具”でも“賢く見せる道具”でもなく、 ひとつの文脈に収まらない仕事を、収まる単位に割るための道具。収まるなら、分けない。
横断分析の結果(一部)は下記となりました。
シングルエージェント: gpt-5.5
提示された文献群を横断すると、江戸川乱歩作品の大きな構造は、怪異の出現、社会的騒動、不可解な犯罪、探偵的解明、そしてさらなる反転にある。
「D坂の殺人事件」では、明智小五郎は心理と論理を武器にした若き探偵として現れる。そこでは証言の不確かさや心理分析が重視される。
一方、少年探偵団系作品では、明智はすでに完成された名探偵であり、怪盗二十面相・四十面相・透明怪人・妖怪博士といった怪人たちと、変装とトリックの知恵比べを展開する。
全体として、乱歩の物語では、犯罪者は恐怖の対象であると同時に、読者を驚かせる演出家でもある。探偵はその演出を見破り、さらに上位の演出で反撃する。
この「怪人の芝居」と「探偵の逆演出」の応酬こそが、文献群に共通する最大の特徴である。
また、少年探偵団の存在によって、探偵小説は大人だけの知的遊戯ではなく、少年読者が自分も参加できる冒険として再構成されている。
怪奇、推理、冒険、科学、近代都市、宝物、変装、読者への挑戦が一体となり、提示文献群全体は、乱歩的探偵物語の多面的な展開を示している。
サブエージェント: gpt-5.5
対象文献群を横断すると、江戸川乱歩の明智小五郎ものには、「見かけの怪奇や不可能性を、知性によって解体する」という一貫した構造が見える。
『D坂の殺人事件』では、その解体対象は密室的殺人、目撃証言、指紋、犯罪心理である。
一方、少年向け作品群では、解体対象は怪人、魔人、透明人間、妖怪、呪い、秘密基地、変装、奇術、機械仕掛けである。
どちらの場合も、重要なのは「表面を信じないこと」である。
目撃証言、外見、噂、新聞報道、怪奇現象、権威ある人物の姿――それらはすべて偽装されうる。明智小五郎は、その偽装の裏にある心理・仕掛け・構造を読む探偵として描かれる。
また、少年向け作品では、明智の知性に小林少年や少年探偵団の勇気・機転・団結が加わることで、探偵行為が個人の推理から集団的冒険へと広がっている。
全体として、これらの作品群は、怪奇趣味、都市的恐怖、変装、機械仕掛け、美術品への欲望、少年の冒険、名探偵と怪盗の知恵比べを反復しながら、「恐怖は理性によって見破れる」というメッセージを娯楽的に展開している。
シングルエージェント: claude-opus-4-8
提示された江戸川乱歩10編は、明智小五郎を共通の軸としながら、(1) 推理を主眼とする大人向け本格(『D坂』、および国際色を加えた『黄金仮面』)と、(2) 怪人対少年探偵団の定型的活劇(少年探偵団シリーズ)の二系統に分かれる。両系統は、変装による正体の隠蔽と暴露、注意力の盲点を突くトリック、知恵の対決という基底を共有しつつ、語り口・読者対象・犯罪の性質・解決の置き方において対照をなす。
横断的に見れば、乱歩作品は「同一の探偵像と宿敵像」「予告状・変装・隠れ家・種明かし」という反復可能なパーツを確立し、それを大人向けでは論理に、少年向けでは活劇に振り分けて展開した、と整理できる。特に少年向けシリーズは、構造・人物・小道具・決め台詞に至るまで高度に定型化されており、シリーズものとしての「型の反復」が最大の特徴である。
サブエージェント: claude-opus-4-8
本作品群は、江戸川乱歩という単一の著者が、明智小五郎という単一の探偵を軸に、約30年にわたって展開した作品系列である。要約から見る限り、これらは「外見の不確かさ・怪異を、理性と洞察で見抜く」という一貫した合理主義的骨格を共有しつつ、(1)大人向けの心理的・倒錯的本格短編(『D坂』)、(2)大衆向け国際冒険活劇(『黄金仮面』)、(3)少年向けのシリーズ冒険譚(残り6作)という三つの層に分化している。
最も重要な横断的発見は、明智小五郎が「内省的な心理探偵」から「万能のヒーロー名探偵」へと造形を変容させた点、および怪奇・SF的外観を一貫して合理的トリックに還元する「啓蒙的合理主義」が全作品の通奏低音となっている点である。
なお本分析は8作品の構造化要約のみに基づくものであり、各作品の初出年代の正確な前後関係や、作品間の影響関係の詳細は要約の範囲では断定できない。
今後さらに調べるべき論点として、(1)各作品の正確な初出年代の確定とそれに基づく明智像の変遷の時系列的検証、(2)『D坂』の心理学的探偵から少年向けの行動的探偵への転換点の特定、(3)海外文学(ポオ・ドイル・ルブラン・ウェルズ)からの影響の具体的内実、(4)差別的表現の歴史的文脈の整理、が挙げられる。
シングルエージェント: gemini-3.5-flash
江戸川乱歩のこれら6つの作品群を横断的に分析すると、そこには「日常の亀裂から現れる怪奇(怪盗・魔人・お化け)を、徹底的に合理的なトリック(変装・錯覚・からくり)に還元する、名探偵・明智小五郎の論理の勝利」という一貫した構造が見て取れます。
特に少年向けの作品群では、大人の警察官が「目に見える証拠」や「おとなの常識」に惑わされて翻弄されるのに対し、小林少年率いる少年探偵団(チンピラ別働隊、ポケット小僧)は、「子どもの身軽さ」「おとなが油断する隙」を突いて、BDバッジなどの即興の知恵を用いて、見事に怪盗の足元をすくいます。
乱歩の構築したミステリ世界は、単なる謎解きにとどまらず、変装と替え玉を駆使して「どちらが本物で、どちらが偽物か」を競い合う、探偵と怪盗のきわめてスリリングな「二重写しの遊戯(ゲーム)」であり、それが昭和の都市空間の変遷(モダンな万博から戦後の防空壕の廃墟まで)を背景に、今なお色褪せないサスペンスを放ち続けているのです。
サブエージェント: gemini-3.5-flash
これらの文献は、江戸川乱歩のミステリが「書斎での論理パズル(D坂)」から「国際的・猟奇的スペクタクル(黄金仮面)」、そして「少年向けの科学的冒険活劇(少年探偵団シリーズ)」へと展開していく過程で、一貫して「人間の心理的死角」と「本物と偽物の境界の曖昧さ」をテーマにしてきたことを示しています。
明智小五郎と怪盗たちは、変装とすり替えという鏡像の技術を駆使して戦い、最終的にはどんなオカルトやSF的欺瞞も、名探偵の「楽屋裏(仕掛け)を見抜く合理の眼」によって物理的なトリックへと回収されていきます。この対決のダイナミズムこそが、提示された文献群から見える乱歩ミステリ構造の真髄です。
まとめ
サブエージェントとは、独立した文脈を持つ別のエージェントに、ゴールを渡して委ねる仕組みです。
ツール呼び出しが「決まった関数を呼ぶ」ことなら、サブエージェントは「もう一人に任せる」こと。
シングルエージェントで足りるならシングルで十分ですが、 冗長な出力で文脈が膨らむ/件数が多くて直列だと遅い/役割を分けたい ときに効きます。
次は、サブエージェントの構成パターンについて書く予定です。
elatt では、こうした判断を実運用の中で日々やっています。設計の相談や、一緒に作る仲間の話は[採用情報]や[お問い合わせ]から気軽にどうぞ。