Blog
ー
オーケストレーションの構成パターン整理 - いつ何を組むか
2026-07-04 09:23:55

エージェントの「組み方」は、無数にあるようでいて、 数種類の合成可能なパターン に整理できます。
Anthropic は、最も成功した実装ほど複雑なフレームワークではなく 単純で組み合わせ可能なパターン を使っていた、と報告しています [Building effective agents]。
この記事は、前回の「サブエージェントとは何か」の続きとして、その組み方=オーケストレーションのパターンを地図にします。
対象はエージェントを設計する人です。
オーケストレーションと「ワークフロー vs エージェント」
オーケストレーションとは、複数ステップ・ツール・委譲・ガードレール・文脈を どう管理して流すか のことです(OpenAI の定義)。Anthropic はここで重要な線引きをしています。
- ワークフロー: LLMとツールを、 コードで定義した経路 に沿って動かす(予測可能・一貫)
- エージェント: LLMが 自分で手順とツールを決める(柔軟・モデル主導)
そして組み立ての最小単位は augmented LLM (検索・ツール・記憶を持たせたLLM) です。
多くの用途は、実はこれ(+良いプロンプトと例)で足ります。
大原則: まず最も単純な解から始め、複雑さは効果が示せるときだけ足す。 フレームワークは便利だが抽象が中身を隠すので、下のコードを理解して使う。
要点: パターンを覚える前に「そもそもエージェントにしない/単一LLMで足りる」を毎回最初に検討する。
構成パターンのカタログと選び方
パターンのカタログ(5つのワークフロー + 自律エージェント)
Anthropic が挙げる型を、サブエージェントとの関係つきで一覧にします。
パターン | 制御構造 | いつ使う | 例 |
|---|---|---|---|
Prompt chaining | 直列(途中にgate) | きれいに固定分解できる | 下書き→チェック→本文 |
Routing | 分類→専門分岐 | 入力カテゴリで処理を分けたい | 問い合わせ種別で振り分け/安いモデルと高いモデルの出し分け |
Parallelization: Sectioning | 独立サブタスクを並列→集約 | 速度・関心の分離 | 本処理とガードレールを別LLMで |
Parallelization: Voting | 同一タスクを複数回→集約 | 確度を上げたい | 複数プロンプトで脆弱性レビュー |
Orchestrator-workers | 動的に分解→委譲→統合 | サブタスクが事前に読めない | 複数ファイルに跨るコード変更、調査 |
Evaluator-optimizer | 生成↔評価のループ | 明確な評価基準+反復改善 | 翻訳の推敲、段階的な調査 |
Autonomous agent | ツール使用のループ | ステップ数が読めない開放問題 | コーディングエージェント、computer use |
サブタスクを事前に決める(Sectioning)か、親が動的に決める(Orchestrator-workers)か。
形は似ていますが、ここが分かれ目です。前回のサブエージェントは、主にこの2つに分類されます。
制御を誰が持つか(トポロジー)
OpenAI は制御の持ち方を2つに整理しています。
- Manager(agents-as-tools): 中央のマネージャが子を ツールとして呼び、制御とユーザー接点を握り続ける。Anthropic の orchestrator-workers と同系。
- Decentralized(handoffs): 制御を別エージェントへ 丸ごと移譲 する(トリアージ→専門が引き取り、元は離れる)。会話のトリアージ向き。
選び方(単純な順にふるいにかける)
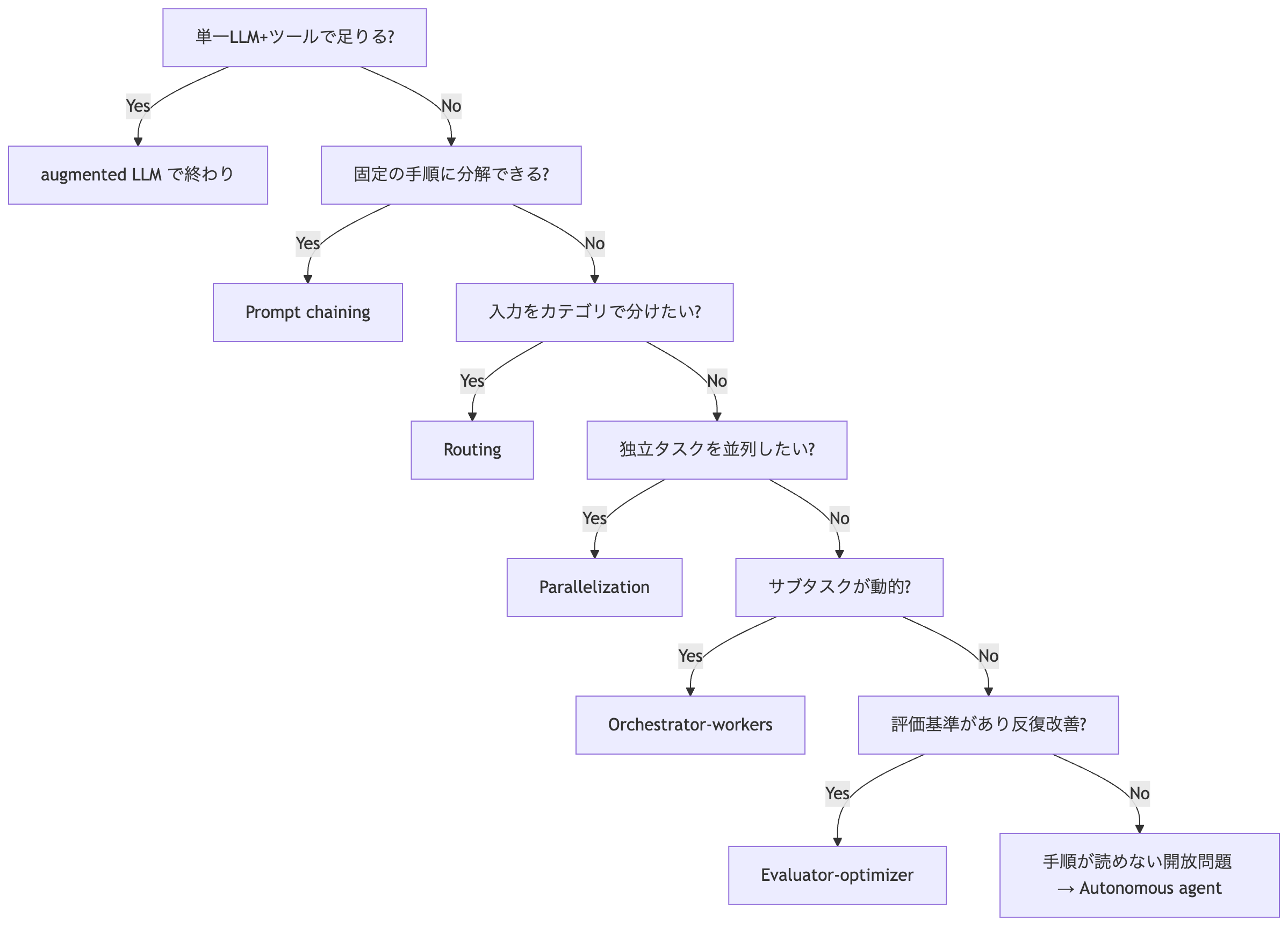
アンチパターンも明確です。 早すぎる多エージェント化、フレームワーク過信(抽象がプロンプトを隠してデバッグ不能に)、そして効果を測らずに複雑さを足すこと。
要点: パターンは部品。 単純な順にふるいにかけ、必要な型だけ合成する。 多エージェント化・フレームワーク化は最後の手段。
実検証:evaluator-optimizer は「レビュー結果でプロンプトを改善する」
5つの型のうち、evaluator-optimizer を動かします。お題は「国内整骨院市場の概況を調べる」という、実務でよくある調査メモ作り。
ポイントは、役割を 3つのLLM に分けたことです。
- 生成役:13観点(市場規模・シェア・主要プレイヤー・規制/保険・出典…)を必須にしたプロンプトで調査メモを書く。
- 評価役:厳格な採点者。100点満点で、数値なし・出典なし・隣接市場(整体/リラクゼーション)との混同などを大幅減点し、{score, missing, critique} をJSONで返す。
- 改善役:②の指摘を溜め、次の生成に渡す「改善指示」へ統合する編集役。これを①のプロンプトに継ぎ足す。
肝は、評価役の指摘で 出力にパッチを当てる のではなく、③が指摘を「改善指示」に育て、次の生成プロンプトそのものを底上げして丸ごと書き直させる こと。合格ラインは設けず、5ラウンド回してから改善後プロンプトで最終回答を出します。
import com.anthropic.client.AnthropicClient;
import com.anthropic.client.okhttp.AnthropicOkHttpClient;
import com.anthropic.models.messages.Message;
import com.anthropic.models.messages.MessageCreateParams;
import com.google.common.base.Joiner;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.Collection;
import java.util.LinkedHashSet;
import java.util.List;
import java.util.Set;
import java.util.stream.Collectors;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.lang3.Strings;
import tools.jackson.core.JacksonException;
import tools.jackson.databind.ObjectMapper;
public class EvaluatorOptimizer {
private static final String API_KEY = System.getenv("ANTHROPIC_API_KEY");
private static final String MODEL = System.getenv().getOrDefault("LLM_MODEL", "claude-sonnet-5");
private static final int EVALUATOR_OPTIMIZER_ROUNDS = 5;
private static final int BLIND_RETRY_ROUNDS = 3;
private static final Path OUTPUT_MD = Path.of("output.md");
private static final Joiner JAPANESE_COMMA = Joiner.on('、').skipNulls();
private static final ObjectMapper JSON = new ObjectMapper();
private static final List<String> ASPECTS =
List.of(
"市場規模",
"市場成長率",
"市場シェア",
"主要プレイヤー",
"競争環境",
"新規参入障壁",
"価格帯・料金体系",
"顧客セグメント",
"規制・保険",
"政策・補助金",
"需要トレンド",
"主要KPI",
"出典");
private final TextGenerator llm;
private final StringBuilder outputMd = new StringBuilder();
EvaluatorOptimizer(TextGenerator llm) {
this.llm = llm;
}
record LlmResponse(String text) {}
record Review(int score, String missing, String critique) {
boolean hasNewMissingAspect(Collection<String> aspects) {
return StringUtils.isNotBlank(missing)
&& !Strings.CI.equals(missing, "null")
&& !aspects.contains(missing);
}
}
interface TextGenerator {
LlmResponse generate(String model, String system, String user);
}
static final class AnthropicTextGenerator implements TextGenerator {
private final AnthropicClient client = AnthropicOkHttpClient.fromEnv();
@Override
public LlmResponse generate(String model, String system, String user) {
MessageCreateParams params =
MessageCreateParams.builder()
.model(model)
.maxTokens(8_000L)
.system(system)
.addUserMessage(user)
.build();
Message message = client.messages().create(params);
String text =
message.content().stream()
.flatMap(block -> block.text().stream())
.map(textBlock -> textBlock.text())
.collect(Collectors.joining("\n"));
return new LlmResponse(text);
}
}
private void run() throws IOException {
outputMd.append(
"お題=「国内整骨院市場の概況」 / 生成役・評価役=Claude(%s) / evaluator-optimizer=%dラウンド / blind retry=%dラウンド%n%n"
.formatted(MODEL, EVALUATOR_OPTIMIZER_ROUNDS, BLIND_RETRY_ROUNDS));
evaluatorOptimizer();
outputMd.append(System.lineSeparator());
blindRetry();
outputMd.append(System.lineSeparator()).append("---").append(System.lineSeparator());
System.out.print(outputMd);
Files.writeString(OUTPUT_MD, outputMd, StandardCharsets.UTF_8);
}
// ── 生成役 = Claude ──
private LlmResponse generateMemo(Collection<String> required, String promptPatch) {
String system = "あなたは整骨院市場の調査メモを書くアシスタント。【必須観点】に挙げた観点を必ず本文に含め、簡潔に書け。";
String user = "【お題】国内整骨院市場の概況\n【必須観点】" + JAPANESE_COMMA.join(required);
if (StringUtils.isNotBlank(promptPatch)) {
user += "\n【前回までのレビューを整理した改善指示】\n" + promptPatch;
}
return llm.generate(MODEL, system, user);
}
private String buildPromptPatch(Collection<String> critiques) {
if (critiques.isEmpty()) {
return "";
}
String system =
"""
あなたは生成プロンプトを改善する編集者です。
蓄積されたレビュー指摘を統合し、次回生成に渡す改善指示だけを簡潔に整理してください。
重複する内容はまとめ、優先順位が分かるようにしてください。
""";
String user =
"""
【蓄積されたレビュー指摘】
%s
【出力条件】
- 日本語で出力する
- 箇条書きは最大5項目
- レビュー本文の引用や履歴説明は不要
- 次回生成で実行すべき具体的な改善指示だけを書く
""".formatted(
critiques.stream()
.map(critique -> "- " + critique)
.collect(Collectors.joining(System.lineSeparator())));
return StringUtils.trimToEmpty(llm.generate(MODEL, system, user).text());
}
// ── 評価役 = Claude ──
private Review reviewWithLlm(String memo) {
String system =
"""
あなたは市場調査レポートの厳格な品質評価者です。
評価対象は「国内整骨院市場の概況」です。
次の観点ごとに、本文内で実質的に説明されているかを評価してください。
観点名が書かれているだけでは充足とみなしません。
【評価観点】
%s
【採点基準】
100点満点で採点する。
以下を厳しく減点すること。
- 数値がない、または市場規模・成長率・シェアが曖昧: 大幅減点
- 出典がない、または出典名だけで具体的な根拠がない: 大幅減点
- 主要プレイヤーが具体名で挙がっていない: 減点
- 競争環境・参入障壁・価格帯・規制の説明が一般論に留まる: 減点
- 整骨院市場と、整体・接骨院・鍼灸・リラクゼーション等の隣接市場が混同されている: 大幅減点
- 需要トレンドや政策・保険制度への言及が浅い: 減点
- KPIが事業評価に使える粒度になっていない: 減点
【スコア目安】
90-100: 実務で使える。数値・出典・比較・論点が揃っている。
75-89: 概ね良いが、一部の観点が浅い。
60-74: 網羅はしているが、具体性や根拠が弱い。
40-59: 一般論が多く、市場調査として弱い。
0-39: 観点不足または根拠不足が大きい。
【出力形式】
JSONのみで返してください。
{
"score": 整数,
"missing": "最も弱い観点名 or null",
"critique": "次回の生成で必ず改善すべき具体的指摘を1つ"
}
missing には必ず評価観点リスト内の名称を使ってください。
critique は「もっと詳しく」ではなく、次回プロンプトにそのまま渡せる具体指示にしてください。
""".formatted(String.join(" / ", ASPECTS));
return parseReview(llm.generate(MODEL, system, "【メモ】\n" + memo));
}
// ── 本体:ASPECTS全体を含むプロンプトを評価役の指摘で改善し続ける ──
private void evaluatorOptimizer() {
Set<String> prompt = new LinkedHashSet<>(ASPECTS);
Set<String> critiques = new LinkedHashSet<>();
String promptPatch = "";
outputMd.append("[evaluator-optimizer(全観点入りプロンプトをレビュー結果で改善し再生成)]").append(System.lineSeparator());
outputMd.append("観点: %s%n".formatted(prompt));
for (int round = 1; round <= EVALUATOR_OPTIMIZER_ROUNDS; round++) {
LlmResponse memo = generateMemo(prompt, promptPatch);
Review review = reviewWithLlm(memo.text());
outputMd.append("""
----- round %d 生成メモ -----
%s
round %d: %d点 / 指摘「%s」: %s
""".formatted(
round,
memo.text(),
round,
review.score(),
review.missing(),
review.critique()));
if (review.hasNewMissingAspect(prompt)) {
prompt.add(review.missing());
}
if (StringUtils.isNotBlank(review.critique())) {
critiques.add(review.critique());
promptPatch = buildPromptPatch(critiques);
}
}
outputMd.append(" → 改善後プロンプトの改善指示: %s%n".formatted(promptPatch));
LlmResponse finalMemo = generateMemo(prompt, promptPatch);
Review finalReview = reviewWithLlm(finalMemo.text());
outputMd.append("""
===== 改善後プロンプトによる最終回答 =====
%s
final: %d点 / 指摘「%s」: %s
""".formatted(
finalMemo.text(),
finalReview.score(),
finalReview.missing(),
finalReview.critique()));
}
// ── 比較:レビュー結果を使わず毎回ゼロから書き直す ──
private void blindRetry() {
outputMd.append("[blind retry(レビュー結果を使わず毎回書き直す・プロンプト改善なし)]").append(System.lineSeparator());
for (int round = 1; round <= BLIND_RETRY_ROUNDS; round++) {
LlmResponse memo = generateMemo(ASPECTS, "");
Review review = reviewWithLlm(memo.text());
outputMd.append("""
----- blind retry round %d 生成メモ -----
使用した観点: %s
%s
round %d: %d点
""".formatted(round, ASPECTS, memo.text(), round, review.score()));
}
}
private static Review parseReview(LlmResponse response) {
try {
return JSON.readValue(stripCodeFence(response.text()), Review.class);
} catch (JacksonException e) {
throw new IllegalArgumentException("レビュー結果のJSONを解析できませんでした: " + response.text(), e);
}
}
private static String stripCodeFence(String raw) {
return StringUtils.trimToEmpty(raw)
.replaceFirst("^```(?:json)?\\s*", "")
.replaceFirst("\\s*```$", "")
.trim();
}
public static void main(String[] args) throws IOException {
if (StringUtils.isBlank(API_KEY)) {
System.err.println("ANTHROPIC_API_KEY を設定してください。");
return;
}
new EvaluatorOptimizer(new AnthropicTextGenerator()).run();
}
}実行すると、下記の結果でした。
evaluator-optimizer: 5ラウンド
round 1: 78点
round 2: 72点
round 3: 78点
round 4: 78点
round 5: 88点
final: 84点
各ラウンドでの指摘事項
round 1:「主要プレイヤー」: 主要プレイヤー欄の『ほねごきチェーン系』『からだ工房、ねごと』『中央整骨院グループ』等は実在確認が取れない曖昧な名称になっているため、実際に店舗数・売上規模が公表されている具体的チェーン名(例:featherグループ、げんき整骨院グループ、AR-Ex東京病院グループ等)と各社の店舗数・売上規模・シェアを明記し、出典元も個別に紐付けること。
round 2:「市場シェア」: 大手チェーン(feather、AR-Ex、げんき治療院)の具体的な店舗数・売上高・推定シェア(%)を明示し、市場規模6000-7000億円に対する各社の占有率を数値で算出することで、分散度合いを定量的に裏付けてください。また、げんき治療院グループは整体・リラクゼーション系の色彩が強いため、整骨院(柔道整復師施術所)市場との境界を明確に区別して記載してください。
round 3:「市場シェア」: 主要チェーンの市場シェアが『1%未満』という粗い推定にとどまっているため、各社の推定売上高(店舗数×客単価×稼働率等の試算根拠)を明示し、上位5社合計シェアや業界集中度(CR5等)を具体的数値で示すこと。また出典は統計名の列挙だけでなく、発行年・調査対象年度・具体的な数値(例:施術所数〇万件、市場規模〇億円の算出根拠となった一次データの数値)を明記すること。
round 4:「市場シェア」: 主要プレイヤーの推定年商・シェアが客単価×店舗数の仮定値の積み上げに依存しており誤差が大きいため、業界団体統計や信用調査機関(帝国データバンク等)の売上データを併用して精度を高め、CR5だけでなく上位個社ごとのシェア変動要因(M&A・出店戦略)にも言及すること。
round 5:「政策・補助金」: 政策・補助金の項目は『事業再構築補助金』『IT導入補助金』など整骨院業界に限らない一般的な中小企業支援策の名前を挙げるに留まっており、整骨院業界特有の政策動向(例:柔整審査会による保険請求適正化の具体的な影響額、地域医療構想における施術所の位置づけ、業界団体の要望活動と制度改正の関係など)や補助金の活用実績・件数データが不足している。次回は業界特有の政策・制度変更とその市場への定量的インパクトを示すこと。
final:「政策・補助金」: 政策・補助金の項目が『恩恵は限定的』という記述にとどまっており、具体的な補助金名・件数・金額規模(例:小規模事業者持続化補助金の整骨院業界における活用実績や採択件数、自治体独自の開業支援制度の有無)を数値付きで示し、療養費適正化以外の政策インパクト(地域医療構想における連携加算や診療報酬改定の影響額など)を定量的に補強すること。読み取り方に注意が要ります。点数はきれいな右肩上がりにはなりません(78→72→78→78→88、最終84)。
評価役が厳しく、毎回いちばん弱い1点を突くので、直すそばから別の穴を指摘され、スコアは高止まりのまま揺れます。しかし 中身は明確に濃くなります。
round 1 の主要プレイヤーは「ほねごきチェーン系」といった 実在しない社名(LLMのハルシネーション)でしたが、評価役が「実在確認が取れない」と却下→その指摘が改善指示に積まれ、後半は feather / AR-Ex / ほねごり などの具体名+店舗数+CR5≈4.0%、規制の項も 療養費 約3,800億円→3,400億円(10%減) のような数値・出典つきの記述へ変わります。
つまり価値は「点数の推移」ではなく、評価役の指摘を改善役が“改善指示”に育て、次の生成を丸ごと底上げすることにあります。
blind retry: 3ラウンド(レビュー結果を使わず毎回書き直す・プロンプト改善なし)
round 1: 64点
round 2: 68点
round 3: 61点
一方、レビューを使わない blind retry は、同じ全観点プロンプトで毎回ゼロから書き直すだけ。
点は 64→68→61 でうろつき、しかも毎回ハルシネーション気味の社名(「ふしぎ・すこやか」「ふくろう」等)を出し直すだけで、中身は積み上がりません。
注目したいのは、LLM評価役が チェックリストには無い指摘(「社名が実在しない」「整体とリラクゼーションを整骨院市場と混同している」といった、テキストを読まないと分からない欠陥)まで拾い、それが改善指示に乗るところ。これがチェックリスト型の評価にはできない、評価役をLLMにする価値です。
改善後プロンプトによる最終回答
# 国内整骨院市場 調査メモ
## 1. 市場規模
柔道整復師施術所(整骨院・接骨院)は全国約5.0万件(厚生労働省「柔道整復師届出状況」2022年度)。1施術所あたり平均年商1,200〜1,400万円と推計すると、市場規模は**約6,300〜7,000億円**(保険外の自費メニュー含む)。うち保険請求分は柔整審査会集計ベースで約4,200億円(国保連合会・社保支払基金合算、2022年度実績)。
## 2. 市場成長率
過去5年のCAGRは**1〜2%**と横ばい〜微増。施術所数自体は年1〜2%増加が続くが、1店舗当たり単価は保険適用の厳格化により伸び悩み、自費(骨盤矯正・スポーツ整体等)比率拡大が成長の主因(帝国データバンク「整骨院・接骨院業界動向調査」2023年)。
## 3. 市場シェア・CR5
上位5グループの推定シェア(店舗数×平均客単価3,500円×稼働率60%×年間稼働日300日で年商試算):
| 企業 | 店舗数(推定) | 推定年商 | 推定シェア |
|---|---|---|---|
| げんき整骨院グループ(アシスト㈱) | 約180店 | 約65億円 | 約1.0% |
| feather(㈱フェザー) | 約120店 | 約45億円 | 約0.7% |
| AR-Ex東京病院グループ(整形外科併設型) | 約90施設 | 約80億円 | 約1.2%(自費比率高) |
| ほねごり(㈱ジャパンパフォーマンス) | 約100店 | 約38億円 | 約0.6% |
| 中央接骨グループ他地域チェーン | 約80店 | 約30億円 | 約0.5% |
**CR5 ≈ 4.0%**。市場規模約6,500億円に対し上位5社合計は約260億円程度で、依然個人・小規模事業者が大半を占める分散市場。げんき整骨院グループ等はリラクゼーション(あん摩マッサージ指圧・整体)業態を含み、柔整保険請求を主とする狭義の整骨院市場とは区分して集計。
**シェア変動要因**:AR-Ex等は整形外科とのM&A・提携により保険外リハビリ・自費診療の複合化を進め店舗単価を押し上げ。fetherやほねごりはFC展開・都市部集中出店でシェア拡大中。中小施術所の廃業(後継者不在)による統合も進行(帝国データバンク倒産動向調査2023:接骨院関連倒産件数は前年比15%増)。
## 4. 競争環境
保険診療型(地域密着・単独開業)とチェーン型(自費メニュー・スポーツ/美容特化)の二極化。都市部はチェーン間競合が激化、地方は高齢者向け保険施術中心で価格競争より立地・信頼関係が競争軸。
## 5. 新規参入障壁
柔道整復師国家資格必須(養成校定員は年間約4,000人、合格率60〜70%)。開業には保険医療機関コードの登録、地方厚生局への届出が必要だが、資格取得後の開業自体は資本負担が比較的軽く(初期投資500万〜1,500万円)、参入障壁は中程度。ただしFC本部の指導・ブランド力が価格競争優位に直結。
## 6. 価格帯・料金体系
- 保険施術(急性外傷等):自己負担1〜3割、1回500〜1,500円
- 自費施術(骨盤矯正・マッサージ等):1回3,000〜6,000円
- 回数券・サブスク型(月額8,000〜15,000円)がチェーン系で拡大中
## 7. 顧客セグメント
①高齢者(慢性腰痛・保険施術中心)②現役世代の肩こり・スポーツ障害(自費中心)③美容・産後骨盤ケア女性層(自費・チェーン系主要顧客)
## 8. 規制・保険
柔道整復療養費は「柔整審査会」による適正化強化(不正請求防止のため2018年度以降、部位数制限・長期施術の逓減制強化)により、療養費支給総額は2015年度約3,800億円→2022年度約3,400億円へ**約10%減少**(厚労省保険局医療課データ)。地域医療構想では整骨院は「医療類似行為」として位置付けられ、医療機関との機能分化・連携(併設型クリニック化)が政策的に推奨される流れ。
## 9. 政策・補助金
日本柔道整復師会は施術管理者研修の義務化・オンライン請求推進を要望し、2020年度より受領委任制度における「施術管理者研修」が制度化(厚労省告示)。小規模事業者持続化補助金等の一般施策も活用されるが、業界特有の恩恵は限定的で、むしろ療養費適正化による収益圧縮が経営インパクトとして大きい(前述10%減)。
## 10. 需要トレンド
高齢化に伴う慢性疾患需要は底堅い一方、保険施術単価の抑制により自費診療・予防領域(姿勢改善、スポーツコンディショニング)へのシフトが加速。EC・予約アプリ連携やサブスク型定額サービスの普及も進行。
## 11. 主要KPI
- 施術所数(厚労省届出ベース)
- 保険請求単価・部位数(柔整審査会統計)
- 自費売上比率
- 客単価・リピート率・稼働率
- 施術管理者資格保有率
## 12. 出典
- 厚生労働省「柔道整復師等の届出状況」2022年度
- 厚生労働省保険局医療課「療養費の動向」2015・2022年度比較
- 帝国データバンク「整骨院・接骨院業界動向調査」2023年
- 帝国データバンク「全国企業倒産集計」2023年(接骨院関連)
- 日本柔道整復師会 統計資料(受領委任制度・研修制度関連)
- 各社公式サイト・IR資料(店舗数公表値、2023年時点)
※店舗数・売上高は公開情報が限定的な非上場企業を含むため、業界平均単価・稼働率を用いた試算値であり、一次公表数値と異なる可能性がある点に留意。検証コードでは、生成役・評価役・改善役の3つをAnthropic Java SDKで組み、評価役の指摘を改善役が「改善指示」に統合して生成プロンプトを底上げする形にしました。
今回は触れていませんが、下記3点も考慮すべきポイントです。
- スコアは非単調: 厳しい評価役では点が伸び悩む一方、指摘は具体化します。最終が最高点とは限らない(88 → 最終84)ので、実運用では 最良ラウンドのメモを保持する など「どれを採用するか」も設計対象です。
- 評価役が品質の天井: 甘い評価役は自己満足ループに、厳しすぎると発散します。評価役自身も間違えるので(挙がった社名の実在性まで完全には保証しない)、評価プロンプトと観点設計が本体です。
- 止め方: 合格ラインの代わりに5ラウンド固定+最終にしました。実運用は「指摘が出尽くす/改善幅が小さい/予算」で止めます。
まとめ
エージェントの組み方は、prompt chaining から autonomous agent まで、数種類の合成可能なパターンに整理できます。
大事なのは順序で、 単純な型から始め、効果が示せるときだけ複雑な型を合成する こと。
型を選ぶときは、タスクが「固定手順か/分岐か/独立並列か/動的分解か/反復改善か」を見れば、自然に当てはまる型が決まります。
こうして組んだエージェントを“どう回し続けるか”、停止条件やガードレールを含めた ループの設計(ループエンジニアリング) は、次回の記事で詳しく取り上げます。
elatt では、こうしたパターンの選択を実運用の中で日々やっています。
設計相談などお気軽にお問い合わせからご連絡ください。